


The Text-to-Text Revolution and Economics (AI Integration 1/4)

About the AI Integration Blog Post Series
This is the first in a four-part series based on my teaching at Federal Reserve workshops, Carnegie Mellon, Wharton, and the upcoming NLP Economics: Fundamentals to Frontier Summer school in Italy. I'm focusing on AI agents and integrated workflows—the biggest challenge my students face moving beyond "just prompt ChatGPT" to systematic AI integration that delivers bigger productivity gains.
From Finance PhD to AI Integration
As a Finance PhD student at Carnegie Mellon working on using the then-frontier deep learning models to predict stock price reactions to earnings reports, I was deep in the weeds of machine learning literature. Language models existed then, though they weren't very large by current standards. These systems generated text by predicting the next word, but I saw limited utility in what seemed like fancy autocomplete. When Google researchers published their T5 paper "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer" in 2019, unifying translation, summarization and other NLP tasks under one framework, I thought it was just another NLP advance. I was wrong about the scope.
T5's insight was deceptively simple: every language task could be reframed as text-to-text generation. Translation became "translate English to French: [text]" → "[French text]". Summarization became "summarize: [text]" → "[summary]". Instead of specialized models for each task, one framework handled them all through different prompts.
What seemed minor then, I now remember as foreshadowing something much larger. If different NLP tasks could be unified under a text generation framework, what about different research tasks? After all, much of research work involves manipulating words—reading literature, synthesizing arguments, drafting hypotheses, revising manuscripts. Perhaps these too could be transformed into language tasks.
I don't know how far AI workflows will ultimately reshape our field or whether it will make it better or worse, but in light of advances since T5, I can't help but be fascinated to explore the possibilities. There's something thrilling about the introspective self-experimentation of doing research projects differently than before and seeing the outcomes—experimenting with how far AI integration can go. This is the first of four posts describing key concepts and tools in this exploration.
These posts won't contain complete solutions, but rather outline the tools we need to build them—both technical tools like agentic capabilities that turn model predictions into decisions about editing specific documents, and methodological frameworks for thinking systematically about our own workflows. The challenge, I'll argue, isn't just technical—it's methodological: learning to decompose our workflows into discrete steps, then rebuild them to work with AI rather than just using it.
While there's fascinating work on AI agents for research (like AlphaEvolve), that's not our focus here. Instead, we're concentrating on integrating existing LLM capabilities into human workflows, rather than building AI solutions that handle research autonomously.
The 44-Percentage-Point Gap
The scale of potential workflow transformation becomes clearer when you examine what tasks could theoretically be automated. An early paper analyzing generative AI's potential labor market effects—one I use to motivate my AI business and society class at Wharton—reveals a striking pattern (though it must be noted that the researchers analyzed occupation descriptions rather than actual implementation effects, so this represents theoretical potential rather than realized outcomes).
Their key finding: LLMs alone (think ChatGPT in your browser) could significantly speed up more that half of the tasks 1.8% of all jobs face. But LLMs integrated with software and workflows? That jumps to 46% of all jobs. While I don't expect these specific numbers to hold as AI develops, the core insight about integration being the crucial multiplier is profound.
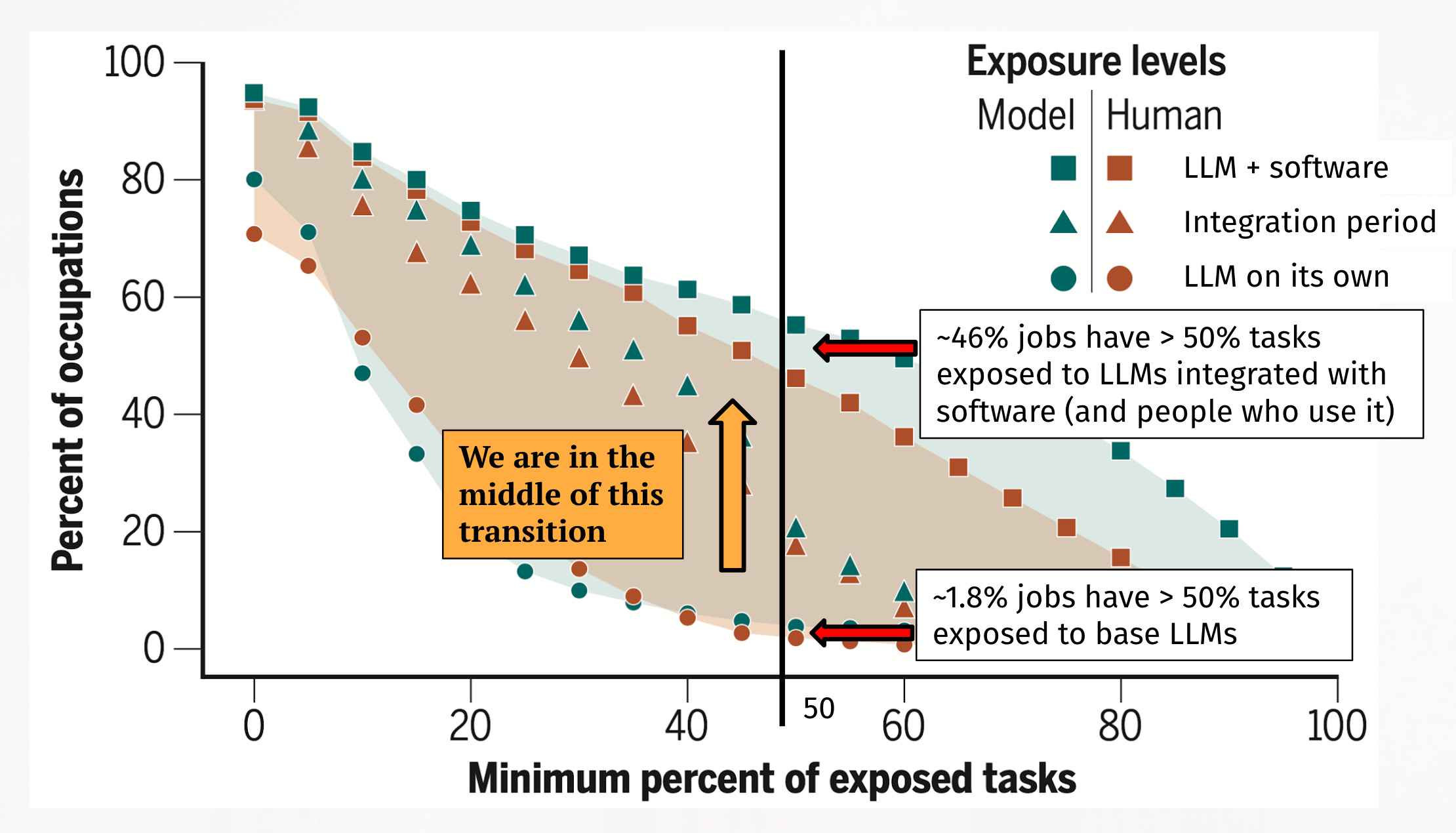
That gap—from 1.8% to potentially 46% of jobs having more than half of their tasks integrated with AI—represents the integration challenge. The difference between typing into a chat interface and having AI embedded in your actual work processes is the difference between marginal impact and economy-wide transformation. It shifts our attention from AI models to how they are used.
This insight parallels T5's revelation: just as T5 showed that different NLP tasks could be unified under the language model framework, this research shows that tasks across different jobs can be automated under that same framework. The unification isn't just technical—it's economic.
The Reflexive Opportunity
The breadth of potential automation creates a peculiar opportunity for economists: we're studying automation while being automated ourselves. Unlike studying factory robots from the outside, we're active participants in AI automation—and this gives us unique insights impossible to get any other way.
Consider the research pipeline: literature review → synthesis → outline → draft → revision → publication. Each step involves manipulating text—exactly what language models excel at. Reading papers and extracting key insights? Text processing. Synthesizing arguments across studies? Text transformation. Drafting hypotheses and structuring arguments? Text generation. The tools of economic research are increasingly the targets of economic automation analysis.
This participation offers remarkable research advantages. When I study AI's impact on labor markets, I'm simultaneously experiencing it in my own workflow. The predictions I make about workplace transformation are informed by tools actively transforming my workspace. The economist studying AI adoption is adopting AI to study AI adoption—creating insights that external observation simply cannot provide.
I'm not alone in this reflexive experimentation. For example, Anton Korinek's comprehensive survey in the Journal of Economic Literature systematically catalogs dozens of use cases for LLMs in economic research, from ideation to mathematical derivations. Alejandro Lopez-Lira maintains a living collection of research prompts he uses "over and over" in his work. Both economists are simultaneously studying AI's capabilities and integrating these tools into their own research practice—embodying the reflexive opportunity I'm describing.
Studying vs Shaping AI Adoption
That 44 percentage point gap between standalone and integrated LLMs makes precision about integration methods crucial. But often we miss the reflexive opportunity. We tend to view AI as an exogenous shock affecting productivity, paying much less attention to how we *shape* our own AI adoption—and therefore the productivity outcomes. An LLM tool in a browser or via API isn't much use alone.
This blind spot is reinforced by the literature itself. AI research focuses on general automation challenges and end-to-end models like Alpha Evolve. Economics treats AI as a technological shock with effects to be studied. Both miss the integration challenge. While it's possible that future AI will figure out efficient workflows without us needing to focus on integration, it feels rather irresponsible not to discuss how we can integrate these tools today.
Here's why methodology matters: AI is not an exogenous shock. Our agency determines the outcomes. There's no sense in which AI's economic effects will be automatic. When my coauthors and I showed that LLMs can digitize historical tables 100 times cheaper than traditional outsourcing with comparable quality, that wasn't an automatic result of "using AI"—it required systematic integration of the tool into a specific research workflow.
This is why I focus on these integration methodology questions. If research inputs can become 100 times cheaper through systematic integration, understanding how to achieve such gains seems worth exploring systematically rather than leaving to chance.
Preview of Next Posts
The arc from T5 to today reveals a pattern: T5 unified NLP tasks under the language modeling framework, and now we're seeing tasks across the entire economy unified under the LLM framework. But realizing this potential requires custom integrations—and we're not focusing on those integrations nearly enough.
But here's the methodological puzzle: how do we bridge that 44 percentage point gap between standalone and integrated LLMs? The answer isn't just better prompts or more powerful models—it's building systems that can act on LLM outputs. When I showed that LLMs could digitize historical tables 100x cheaper, the breakthrough wasn't the language model's text generation capabilities. It was the surrounding system that could take those text outputs, validate them against known patterns, flag inconsistencies for human review, and systematically process thousands of documents.
This is why the next post focuses on compound AI systems and agents—not because agents are the end goal, but because they're an important part of the infrastructure for systematic integration. I'll examine how LLMs need external components for verification and the "integration friction" that prevents efficient AI adoption in research workflows. This covers integration frameworks that enable AI to interact with environments, focusing on systematic workflows where LLM outputs become structured actions: editing specific documents, querying databases, orchestrating multi-step processes.
The second post examines agent failure modes—why sophisticated systems like OpenAI's Operator and Deep Research often underperform despite impressive demos. I'll talk about the compounding error problem in GUI automation and the invisible failure challenge in research synthesis, revealing why general-purpose agents pay a "generality tax" that domain-specific approaches can avoid.
The final post provides concrete implementation guidance—what economists can learn from AI adoption in software development. Drawing from my historical digitization project and the principles of AI coding from software engineering, I'll show how systematic iteration and workflow structure matter more than model capabilities, offering practical takeaways from AI-assisted coding that apply directly to research workflows.
The methodological frontier is wide open. The tools exist. The question is whether we'll approach integration systematically or leave these productivity gains to chance (or others).